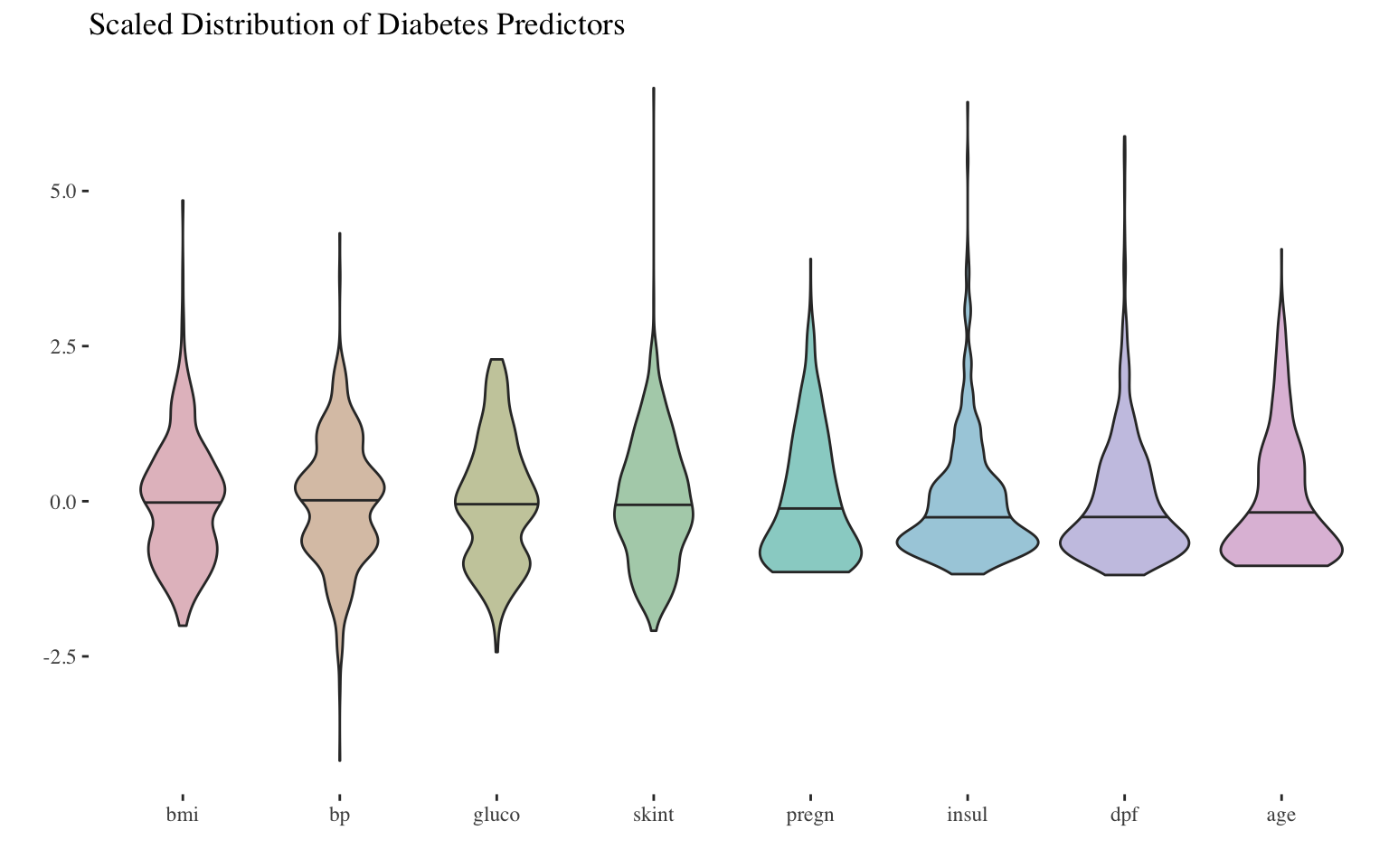
Originally from the National Institute of Diabetes and Digestive and Kidney Diseases, the Kaggle diabetes dataset is a popular and introductory modelling challenge, supported by many Python and R notebooks. The patients are women, at least 21 years old and of Pima Indian heritage. The outcome variable is binary with “0” being persons without diabetes and “1” being persons with diabetes. The task is to predict which persons are diabetic using basic physiological measurements like blood pressure and body mass.
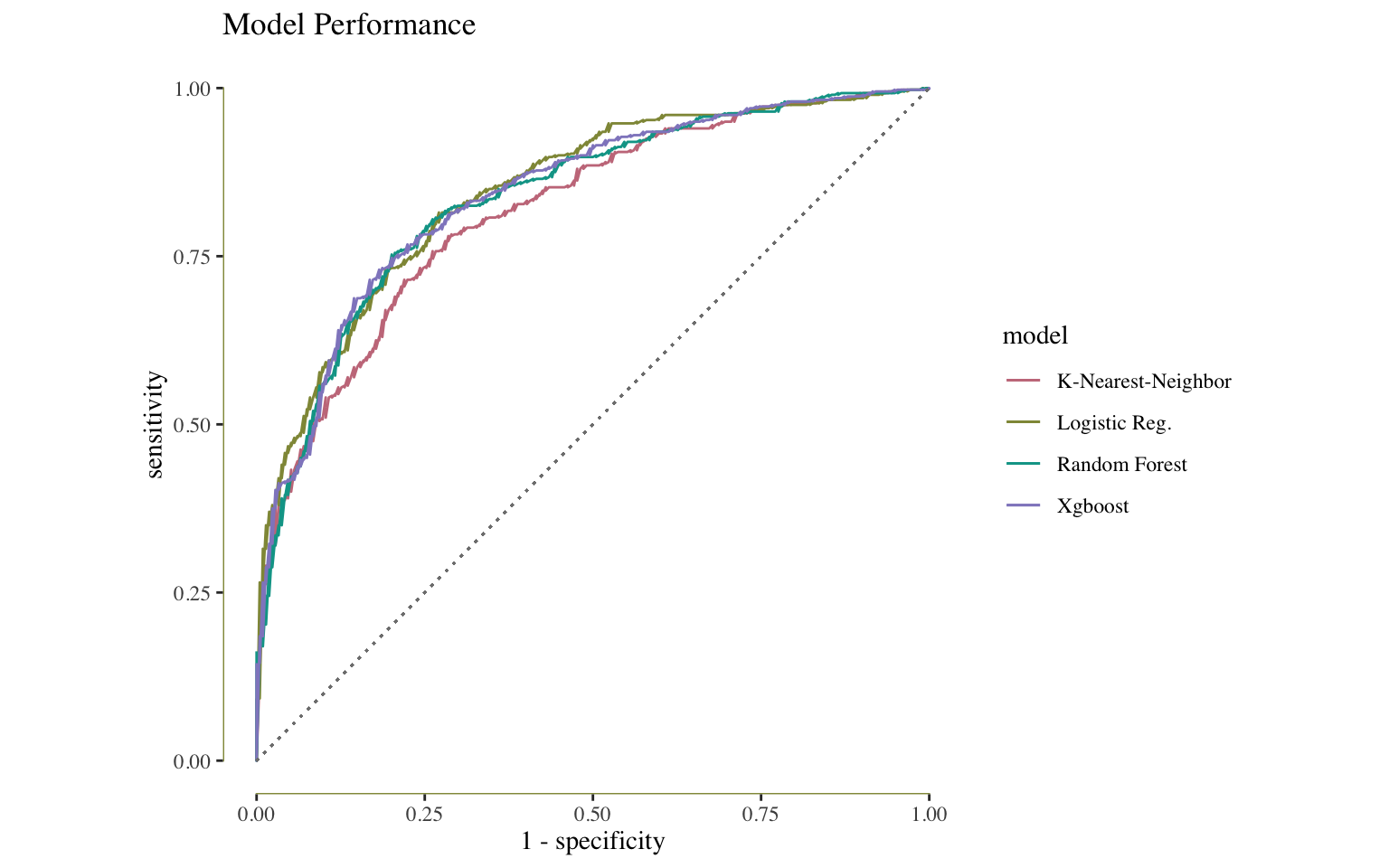
Here, four models are applied to the data and then ranked by area under the curve and accuracy. The four models are logistic regression, k-nearest-neighbor, random forest (ranger) and xgboost. Logistic regression was the best performing when measured by roc_auc (.855) and random forest model was the best performing when measured by accuracy (.772).
The data set was thoroughly explored on Kaggle. Kagglers report that many values were recorded as a zero. For a category like blood pressure or glucose a “0” would be non-sensical. These values were changed to “NA” and imputed using the mice package. Despite imputation and scaling of the data, many outliers remain as shown below. To repeat once more, the data were scaled.
The point of the assignment is to practice the tidy model flow and find the best performing models. Finding the best model means creating an objective measure for evaluation. The diabetes data is a classification problem, but all metrics will be discussed as a reminder for future efforts.
For background, models generally come in two types. “An inferential model is used primarily to understand relationships, and typically emphasizes the choice (and validity) of probabilistic distributions and other generative qualities that define the model.” In predictive models, its strength is more important, i.e. how close its predictions matched the observed data. Silge and Kuhn advise practitioners “developing inferential models . . . to use these techniques even when the model will not be used with the primary goal of prediction.”
The term accuracy is the proportion of the data that are predicted correctly. The Tidy Models book states that “two common metrics for regression models are the root mean squared error (RMSE) and the coefficient of determination (a.k.a. R2). The former measures accuracy while the latter measures correlation A model optimized for RMSE has more variability but has relatively uniform accuracy across the range of the outcome.”
Regression Metrics
metric_set allows for the return of multiple metrics and can be used to return metrics for regression analysis.
regress_metrics <-metric_set(rmse, rsq, mae)
Classification
A classification is usually binary, but it can take on additional classes. A binary classification is where the outcome is one of two possible classes like positive vs. negative or red vs. green. The results often include a probability for each class, like .95 likelihood of occurrence and .05 likelihood of non-occurrence.
For “hard-class” predictions that deal with only the category, not the probability, the yardstick package contains four helpful functions: conf_mat() (confusion matrix), accuracy(), mcc() (Matthew’s Correlation Coefficient), and f_meas(). Three of them could be combined like:
class_metrics <-metric_set(accuracy, mcc, f_meas)
For outcome variables that have multiple classes, the yardstick package contains methods that can be implemented via the “estimator” argument in the sensitivity() function.
# estimator can be "macro_weighted", "macro", "micro"sensitivity(results, obs, pred, estimator ="macro_weighted")
Confusion Matrix
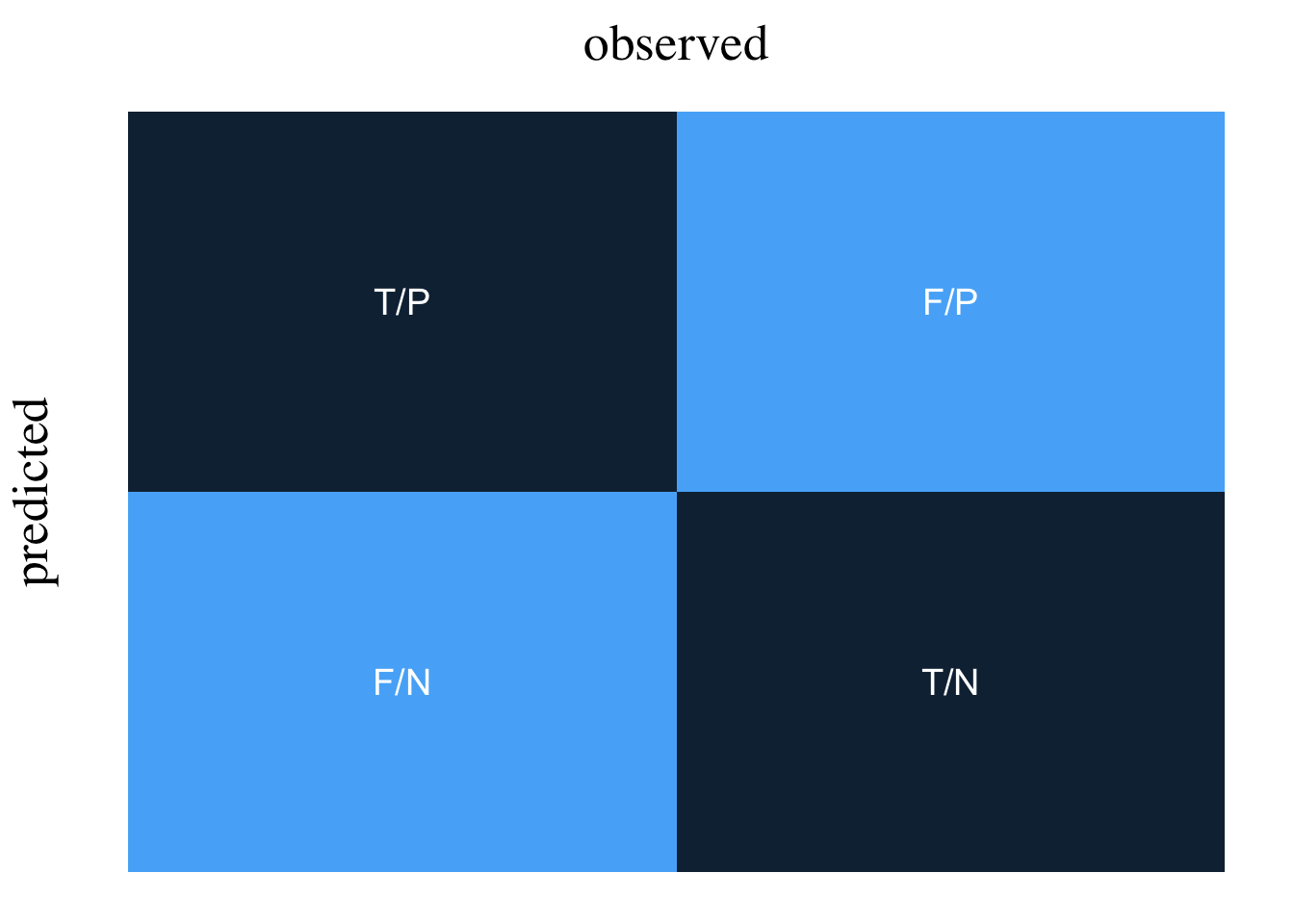
A confusion matrix, also known as an error matrix, reports the performance of a classification model. Where the outcome is one of two classes, the confusion matrix reports the number of observations that were correctly labelled and others that were not. More formally, the confusion matrix is a 2 by 2 table with the following entries:
true positive (TP). A test result that correctly indicates the presence of a condition or characteristic.
true negative (TN). A test result that correctly indicates the absence of a condition or characteristic.
false positive (FP). A test result which wrongly indicates that a particular condition or attribute is present.
false negative (FN). A test result which wrongly indicates that a particular condition or attribute is absent.